Der Artikel zeigt den Transfer von Google Ads API Daten nach Google BigQuery anhand von benutzerdefinierten Reportings, welche individuell konfiguriert werden können.
Mögliche Übertragungswege
Man kann die Google Ads API-Daten auf verschiedene Weisen in BigQuery übertragen. Eine Möglichkeit ist es, einen ETL-Prozess (Extract, Transform, Load) mit einem Drittanbieter-ETL-Tool zu erstellen. Diese Tools extrahieren die Daten aus der Google Ads API, wandeln sie in das richtige Format um und laden sie dann in BigQuery hoch.
Ein weiterer Weg besteht in 2 existierenden Google Transfer Services für Google Ads , die bereits mit BigQuery mitgeliefert werden. Leider hinkt hier häufig die API-Version des Service hinterher und so erhält man nicht die neusten Datentypen, die Google eingeführt hat. Insbesondere in Bezug auf Pmax Kampagnen und deren Asset Groups stellt dies derzeit eine Einschränkung dar, welche es sich lohnt zu überwinden.
Ein einfacher Ansatz, die Daten nach BigQuery zu übertragen, stellt ein Apps Script dar, welches an die eigenen Datenbedürfnisse angepasst werden kann.
Apps Script zur Übertragung von Google Ads API Daten nach BigQuery
Das Script wird in der Google Apps Script Umgebung installiert und täglich ausgeführt. Bei der Ausführung werden die zuvor konfigurierten Tabellen genommen und mit der Google Ads API abgefragt. Anschließend werden die Daten nach Google BigQuery übertragen.
Vor- und Nachteile dieser Lösung
Vorteile:
- Flexibel, auf API Neuerungen kann individuell reagiert werden.
- Datensparsam: Es werden nur konfigurierte Tabellen übertragen.
- Kostengünstig, da keine weiteren Infrastrukturen eingerichtet werden müssen.
Nachteile:
- Tägliche Übertragung ist aufgrund der API-Limits nur bedingt möglich.
- Wenn die Daten in Echtzeit benötigt werden, ist diese Lösung nicht geeignet
- Die Daten werden in BigQuery abgelegt, wie sie von der API angeliefert werden. Dies bedeutet, dass zusätzliche Reportings eingerichtet werden müssen, um die Daten für die Analyse aufzubereiten
Installation
- Script installieren
- Übertragungsfenster festlegen
- Daten festlegen mit dem GAQL Query Builder
- Übertragung starten
Script installieren
Das Script von unten mit Copy & Paste in ein Google Ads Script oder Apps Script übertragen. Alle Script-Konfiguration findet in der CONFIG variable statt. Der Rest sollte nur editiert werden, wenn man weiß was man tut.
In der Scriptumgebung muss BigQuery noch als Extra-Service angestellt werden.
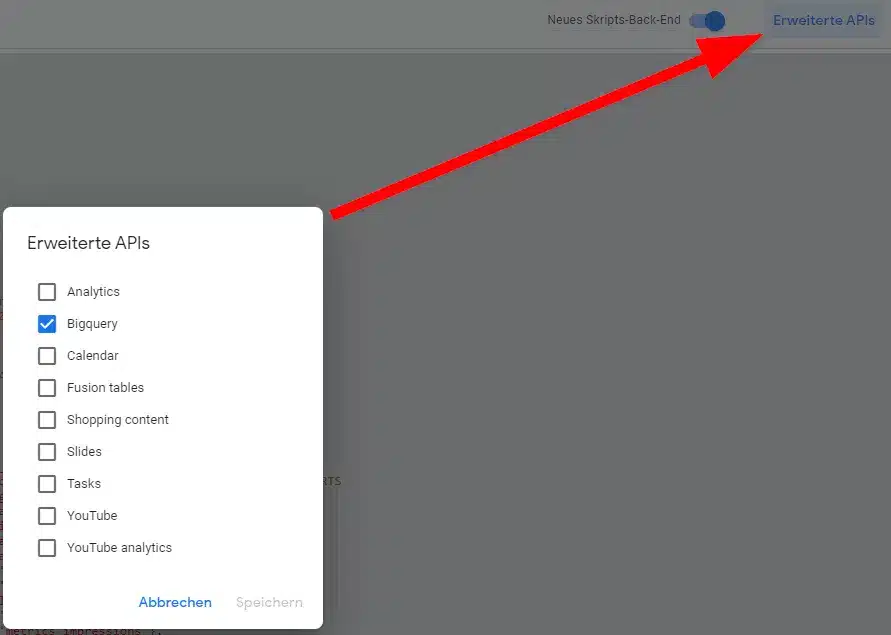
Anschließend muss die Variable des Scripts konfiguriert werden.
Variablen konfigurieren
In der CONFIG Variable werden alle Einstellungen vorgenommen, die das Script benötigt. Die Variablen sollten von der Namensgebung her selbsterklärend sein. Ansonsten hilft der Kommentar dahinter.
BIGQUERY_PROJECT_ID: 'BQPID', // BigQuery Project ID
BIGQUERY_DATASET_ID: 'BGDSID', // BigQuery Dataset ID
LOCATION: 'EU', //Location of the Dataset
EXPERIATION: 2 * 31536000000, // Data Expiration time
DEBUG: { WRITE: true}, // DEBUG Variable if WRITE is false, there is no data send to bigquery. Useful during configuration.
// Truncate existing data, otherwise will append.
TRUNCATE_EXISTING_DATASET: false, // If set to true, dataset will be cleared before data transfer
TRUNCATE_EXISTING_TABLES: false, // If set to true, tables will be cleared before data transfer
// Back up reports to Google Drive.
WRITE_DATA_TO_DRIVE: false, // DEPRECATED
// Folder to put all the intermediate files.
DRIVE_FOLDER: 'INSERT_FOLDER_NAME', //DEPRECATED
// Default date range over which statistics fields are retrieved.
DEFAULT_DATE_RANGE: 'YESTERDAY',//EXAMPLES: 'YESTERDAY' OR '2022-08-01,2022-09-07',
DEFAULT_DATA_LIMIT: '',
CHUNK_SIZE: 5000, // Defines the number of lines the Script will load to Bigquery during one inset operation. Drill this down if you get errors for this.BIGQUERY_PROJECT_ID: 'BQPID', // BigQuery Project ID
BIGQUERY_DATASET_ID: 'BGDSID', // BigQuery Dataset ID
LOCATION: 'EU', //Location of the Dataset
EXPERIATION: 2 * 31536000000, // Data Expiration time
DEBUG: { WRITE: true}, // DEBUG Variable if WRITE is false, there is no data send to bigquery. Useful during configuration.
// Truncate existing data, otherwise will append.
TRUNCATE_EXISTING_DATASET: false, // If set to true, dataset will be cleared before data transfer
TRUNCATE_EXISTING_TABLES: false, // If set to true, tables will be cleared before data transfer
// Back up reports to Google Drive.
WRITE_DATA_TO_DRIVE: false, // DEPRECATED
// Folder to put all the intermediate files.
DRIVE_FOLDER: 'INSERT_FOLDER_NAME', //DEPRECATED
// Default date range over which statistics fields are retrieved.
DEFAULT_DATE_RANGE: 'YESTERDAY',//EXAMPLES: 'YESTERDAY' OR '2022-08-01,2022-09-07',
DEFAULT_DATA_LIMIT: '',
CHUNK_SIZE: 5000, // Defines the number of lines the Script will load to Bigquery during one inset operation. Drill this down if you get errors for this.
Daten festlegen mit dem GAQL Query Builder
Im CONFIG.REPORTS Array können API-Calls werden. Dabei ist jeder Abruf ein Objekt mit den Variablen wie in der Tabelle und im Beispiel gezeigt. Für den Aufbau der API-Calls empfehle ich, dringend den Google Ads API Query Builder zu nutzen, da dieser zunächst zeigt, welche Felder überhaupt kombiniert werden dürfen.
| Variable | Value |
|---|---|
| NAME | Der Tabellen Name in der Google Ads-Api ‚asset_group_product_group_view‚ |
| CONDITION | Hier kann ein „WHERE“ statement eingefügt werden |
| FIELDS | Die im Report gewünschten Felder. |
| RETURN_FIELDS | Felder, welche von der API ohne Anforderung gesendet werden. Notwendig zur Erstellung der Tabellenfelder in BigQuery |
| PARTITION_FIELD | Notwendig, wenn das Feld segemens_date zur Partitionierung genutzt werden soll. In allen anderen Feldern leer lassen. |
Zusätzlich müssen die Felder definiert werden mit
'field.name':{'format':'INTEGER','alias':'field_name'}
| Variable | Value |
|---|---|
| FieldName | Der Name des Feldes wie in der Google Ads Api gezeigt. |
| Format | Datentypen, wie für BigQuery definiert. |
| Alias | FieldName Conversion that works for Google BigQuery as colmun name. |
Wie in dem Code-Beispiel für die eigentlich Query zeigt, wie die Felder während des API-Abrufs genutzt werden.
var query =
'SELECT ' + fieldNames.join(',') +
' FROM ' + reportConfig.NAME + ' ' + reportConfig.CONDITIONS
Hier ein Beispiel für einen vollständig konfigurierten Abruf von ‚ad_group_ad‘:
{
NAME: 'ad_group_ad',
CONDITIONS: '',
FIELDS: {
// Fields have the API-Name in first object level. They inherit the Alias Name an the format for the field in BigQuery tables.
'campaign.id':{'format':'INTEGER','alias':'campaign_id'},
'ad_group.id':{'format':'INTEGER','alias':'adGroup_id'},
'ad_group_ad.ad.responsive_search_ad.descriptions':{'format':'JSON','alias':'adGroupAd_ad_responsive_search_ad_descriptions'},
'ad_group_ad.ad.responsive_search_ad.headlines':{'format':'JSON','alias':'adGroupAd_ad_responsive_search_ad_headlines'},
'ad_group_ad.ad_strength':{'format':'STRING','alias':'adGroupAd_ad_strength'},
'segments.date':{'format':'DATE','alias':'segments_date'},
'campaign.name':{'format':'STRING','alias':'campaign_name'},
'ad_group.name':{'format':'STRING','alias':'adGroup_name'},
'ad_group_ad.resource_name':{'format':'STRING','alias':'adGroupAd_resource_name'},
'ad_group.resource_name':{'format':'STRING','alias':'adGroup_resource_name'},
'metrics.clicks':{'format':'INTEGER','alias':'metrics_clicks'},
'metrics.conversions':{'format':'FLOAT64','alias':'metrics_conversions'},
'metrics.impressions':{'format':'INTEGER','alias':'metrics_impressions'},
'metrics.cost_micros':{'format':'INTEGER','alias':'metrics_cost_micros'}
},
RETURN_FIELDS: {
// Return Fields are fields that we did not ask the API for, but they delivered those too. Needed for correct field Mapping towards BigQuery.
'adGroupAd_ad':{'alias':'adGroupAd_ad','format':'JSON'},
'adGroupAd_ad.id':{'format':'INTEGER','alias':'adGroupAd_ad_id'}
},
PARTITION_FIELD:'segments_date',
},
Übertragung starten
Wenn alle komponenten korrekt konfiguriert wurden, kann der Google Ads Api Abruf gestartet werden.
Das komplette Script zur freien Nutzung:
Hier veröffentliche ich das Script als komplette Version. Ich freue mich auf Kommentare, Feedback, Verbesserungen und natürlich eure Erweiterung der Abrufkonfigurationenen unter (CONFIG.REPORTS).
var CONFIG = {
BIGQUERY_PROJECT_ID: 'BQPID', // BigQuery Project ID
BIGQUERY_DATASET_ID: 'BGDSID', // BigQuery Dataset ID
LOCATION: 'EU', //Location of the Dataset
EXPERIATION: 2 * 31536000000, // Data Expiration time
DEBUG: { WRITE: true}, // DEBUG Variable if WRITE is false, there is no data send to bigquery. Useful during configuration.
// Truncate existing data, otherwise will append.
TRUNCATE_EXISTING_DATASET: false, // If set to true, dataset will be cleared before data transfer
TRUNCATE_EXISTING_TABLES: false, // If set to true, tables will be cleared before data transfer
// Back up reports to Google Drive.
WRITE_DATA_TO_DRIVE: false, // DEPRECATED
// Folder to put all the intermediate files.
DRIVE_FOLDER: 'INSERT_FOLDER_NAME', //DEPRECATED
// Default date range over which statistics fields are retrieved.
DEFAULT_DATE_RANGE: 'YESTERDAY',//EXAMPLES: 'YESTERDAY' OR '2022-08-01,2022-09-07',
DEFAULT_DATA_LIMIT: '',
CHUNK_SIZE: 5000, // Defines the number of lines the Script will load to Bigquery during one inset operation. Drill this down if you get errors for this.
// Lists of reports and fields to retrieve from Google Ads.
REPORTS: [
{
NAME: 'search_term_view',
CONDITIONS: '',
FIELDS: {
'campaign.id':{'format':'INTEGER','alias':'campaign_id'},
'campaign.name':{'format':'STRING','alias':'campaign_name'},
'campaign.status':{'format':'STRING','alias':'campaign_status'},
'campaign.advertising_channel_type':{'format':'STRING','alias':'campaign_advertising_channel_type'},
'search_term_view.search_term':{'format':'STRING','alias':'searchTermView_search_term'},
'search_term_view.status':{'format':'STRING','alias':'searchTermView_status'},
'segments.date':{'format':'DATE','alias':'segments_date'},
'metrics.clicks':{'format':'INT64','alias':'metrics_clicks'},
'metrics.conversions':{'format':'FLOAT64','alias':'metrics_conversions'},
'metrics.conversions_value':{'format':'FLOAT64','alias':'metrics_conversions_value'},
'metrics.cost_micros':{'format':'INT64','alias':'metrics_cost_micros'},
'metrics.impressions':{'format':'INT64','alias':'metrics_impressions'},
}
},
RETURN_FIELDS: {
// Return Fields are fields that we did not ask the API for, but they delivered those too. Needed for correct field Mapping towards BigQuery.
'adGroupAd_ad':{'alias':'adGroupAd_ad','format':'JSON'},
'adGroupAd_ad.id':{'format':'INTEGER','alias':'adGroupAd_ad_id'}
},
PARTITION_FIELD:'segments_date',
}
],
};
// Impose a limit on the size of BQ inserts: 10MB - 512Kb for overheads.
var MAX_INSERT_SIZE = 10 * 1024 * 1024 - 512 * 1024;
/**
* Main method
*/
function main() {
createDataset();
for (var i = 0; i < CONFIG.REPORTS.length; i++) {
var reportConfig = CONFIG.REPORTS[i];
createTable(reportConfig);
}
var jobIds = processReports();
waitTillJobsComplete(jobIds);
}
/**
* Creates a new dataset.
*
* If a dataset with the same id already exists and the truncate flag
* is set, will truncate the old dataset. If the truncate flag is not
* set, then will not create a new dataset.
*/
function createDataset() {
if (datasetExists()) {
if (CONFIG.TRUNCATE_EXISTING_DATASET) {
BigQuery.Datasets.remove(CONFIG.BIGQUERY_PROJECT_ID,
CONFIG.BIGQUERY_DATASET_ID, {'deleteContents' : true});
Logger.log('Truncated dataset.');
} else {
Logger.log('Dataset %s already exists. Will not recreate.',
CONFIG.BIGQUERY_DATASET_ID);
return;
}
}
// Create new dataset.
var dataSet = BigQuery.newDataset();
dataSet.friendlyName = CONFIG.BIGQUERY_DATASET_ID;
dataSet.datasetReference = BigQuery.newDatasetReference();
dataSet.datasetReference.projectId = CONFIG.BIGQUERY_PROJECT_ID;
dataSet.datasetReference.datasetId = CONFIG.BIGQUERY_DATASET_ID;
dataSet.location = CONFIG.LOCATION
dataSet = BigQuery.Datasets.insert(dataSet, CONFIG.BIGQUERY_PROJECT_ID);
Logger.log('Created dataset with id %s.', dataSet.id);
}
/**
* Checks if dataset already exists in project.
*
* @return {boolean} Returns true if dataset already exists.
*/
function datasetExists() {
// Get a list of all datasets in project.
var datasets = BigQuery.Datasets.list(CONFIG.BIGQUERY_PROJECT_ID);
var datasetExists = false;
// Iterate through each dataset and check for an id match.
if (datasets.datasets != null) {
for (var i = 0; i < datasets.datasets.length; i++) {
var dataset = datasets.datasets[i];
if (dataset.datasetReference.datasetId == CONFIG.BIGQUERY_DATASET_ID) {
datasetExists = true;
break;
}
}
}
return datasetExists;
}
/**
* Creates a new table.
*
* If a table with the same id already exists and the truncate flag
* is set, will truncate the old table. If the truncate flag is not
* set, then will not create a new table.
*
* @param {Object} reportConfig Report configuration including report name,
* conditions, and fields.
*/
function createTable(reportConfig) {
if (tableExists(reportConfig.NAME)) {
if (CONFIG.TRUNCATE_EXISTING_TABLES) {
BigQuery.Tables.remove(CONFIG.BIGQUERY_PROJECT_ID,
CONFIG.BIGQUERY_DATASET_ID, reportConfig.NAME);
Logger.log('Truncated table %s.', reportConfig.NAME);
} else {
Logger.log('Table %s already exists. Will not recreate.',
reportConfig.NAME);
return;
}
}
// Create new table.
var table = BigQuery.newTable();
var schema = BigQuery.newTableSchema();
schema.fields = createBigQueryFields(reportConfig);
table.schema = schema;
table.friendlyName = reportConfig.NAME;
table.time_partitioning = {"type":"DAY", "expirationMs":31536000000};
if(reportConfig.PARTITION_FIELD){
table.time_partitioning.field = reportConfig.PARTITION_FIELD
}
table.tableReference = BigQuery.newTableReference();
table.tableReference.datasetId = CONFIG.BIGQUERY_DATASET_ID;
table.tableReference.projectId = CONFIG.BIGQUERY_PROJECT_ID;
table.tableReference.tableId = reportConfig.NAME;
table = BigQuery.Tables.insert(table, CONFIG.BIGQUERY_PROJECT_ID,
CONFIG.BIGQUERY_DATASET_ID);
Logger.log('Created table with id %s.', table.id);
}
function createBigQueryFields(reportConfig){
var bigQueryFields = [];
// Add each field to table schema.
var fieldNames = Object.keys(reportConfig.FIELDS);
for (var i = 0; i < fieldNames.length; i++) {
var fieldName = fieldNames[i];
var bigQueryFieldSchema = BigQuery.newTableFieldSchema();
bigQueryFieldSchema.description = fieldName;
bigQueryFieldSchema.name = reportConfig.FIELDS[fieldName].alias;
bigQueryFieldSchema.type = reportConfig.FIELDS[fieldName].format;
bigQueryFields.push(bigQueryFieldSchema);
}
if(reportConfig.RETURN_FIELDS){
var fieldNames = Object.keys(reportConfig.RETURN_FIELDS);
for (var i = 0; i < fieldNames.length; i++) {
var fieldName = fieldNames[i];
var bigQueryFieldSchema = BigQuery.newTableFieldSchema();
bigQueryFieldSchema.description = fieldName;
bigQueryFieldSchema.name = reportConfig.RETURN_FIELDS[fieldName].alias;
bigQueryFieldSchema.type = reportConfig.RETURN_FIELDS[fieldName].format;
bigQueryFields.push(bigQueryFieldSchema);
}
}
return bigQueryFields
}
/**
* Checks if table already exists in dataset.
*
* @param {string} tableId The table id to check existence.
*
* @return {boolean} Returns true if table already exists.
*/
function tableExists(tableId) {
// Get a list of all tables in the dataset.
var tables = BigQuery.Tables.list(CONFIG.BIGQUERY_PROJECT_ID,
CONFIG.BIGQUERY_DATASET_ID);
var tableExists = false;
// Iterate through each table and check for an id match.
if (tables.tables != null) {
for (var i = 0; i < tables.tables.length; i++) {
var table = tables.tables[i];
if (table.tableReference.tableId == tableId) {
tableExists = true;
break;
}
}
}
return tableExists;
}
/**
* Process all configured reports
*
* Iterates through each report to: retrieve Google Ads data,
* backup data to Drive (if configured), load data to BigQuery.
*
* @return {Array.<string>} jobIds The list of all job ids.
*/
function processReports() {
var jobIds = [];
// Iterate over each report type.
for (var i = 0; i < CONFIG.REPORTS.length; i++) {
var reportConfig = CONFIG.REPORTS[i];
Logger.log('Running report %s', reportConfig.NAME);
// Get data as an array of CSV chunks.
var jsonRows = retrieveAdsReport(reportConfig);
if(CONFIG.DEBUG.WRITE){
var chunks = chunkArray(jsonRows, CONFIG.CHUNK_SIZE)
for(var c = 0; c < chunks.length;c++){
var chunk = chunks[c];
var ndJson = chunk.map(JSON.stringify).join('\n')
var blobData = Utilities.newBlob(ndJson, 'application/json');
var jobId = loadDataToBigquery(reportConfig,blobData);
jobIds.push(jobId);
}
} // END DEBUG WRITE
}
return jobIds;
}
function chunkArray(arr, chunkSize){
var res = [];
for (var i = 0; i < arr.length; i += chunkSize) {
var chunk = arr.slice(i, i + chunkSize);
res.push(chunk);
}
return res;
}
/**
* Retrieves Google Ads data as json and formats any fields
* to BigQuery expected format.
*
* @param {Object} reportConfig Report configuration including report name,
* conditions, and fields.
*
* @return {!Array.JSON} a chunked report in csv format.
*/
function retrieveAdsReport(reportConfig) {
var fieldNames = Object.keys(reportConfig.FIELDS);
var dateRange = setDateRange(CONFIG.DEFAULT_DATE_RANGE);
Logger.log(fieldNames.join(','))
var query =
'SELECT ' + fieldNames.join(',') +
' FROM ' + reportConfig.NAME + ' ' + reportConfig.CONDITIONS
if(reportConfig.FIELDS['segments.date']){
query = query + ' WHERE segments.date BETWEEN ' + dateRange
}
query = query + ' '+ CONFIG.DEFAULT_DATA_LIMIT
var rows = AdsApp.search(query);
var chunks = [];
var chunkLen = 0;
var jsonRows = [];
var totalRows = 0;
while (rows.hasNext()) {
var row = rows.next();
var jsonRow = {}
for (seg in row) {
for(el in row[seg]){
// Transform name of element
var name = el.split(/(?=[A-Z])/).join('_').toLowerCase();
jsonRow[ seg +'_'+ name] = row[seg][el]
}
}
delete jsonRow.campaign_resource_name;
delete jsonRow.shoppingPerformanceView_resource_name;
jsonRows.push(jsonRow)
}
return jsonRows;
}
function transformFields(reportConfig,search,replace) {
var transformedFields = {}
for(field in reportConfig.FIELDS){
var newName = field.replace(search,replace)
transformedFields[newName] = reportConfig.FIELDS[field]
}
transformedFields = transformedFields.map(JSON.stringify).join('\n')
return transformedFields
}
/**
* Creates a BigQuery insertJob to load csv data.
*
* @param {Object} reportConfig Report configuration including report name,
* conditions, and fields.
* @param {Blob} data Csv report data as an 'application/octet-stream' blob.
* @param {number=} skipLeadingRows Optional number of rows to skip.
*
* @return {string} jobId The job id for upload.
*/
function loadDataToBigquery(reportConfig, data) {
// Create the data upload job.
var job = {
configuration: {
load: {
destinationTable: {
projectId: CONFIG.BIGQUERY_PROJECT_ID,
datasetId: CONFIG.BIGQUERY_DATASET_ID,
tableId: reportConfig.NAME
},
//kipLeadingRows: skipLeadingRows ? skipLeadingRows : 0,
//nullMarker: '--',
source_format:'NEWLINE_DELIMITED_JSON',
time_partitioning: {'type':"DAY"},
schemaUpdateOptions:["ALLOW_FIELD_ADDITION","ALLOW_FIELD_RELAXATION"],
schema: {fields: createBigQueryFields(reportConfig)}
}
}
};
if(reportConfig.PARTITION_FIELD){
job.configuration.load.time_partitioning.field = reportConfig.PARTITION_FIELD
}
var insertJob = BigQuery.Jobs.insert(job, CONFIG.BIGQUERY_PROJECT_ID, data);
Logger.log('Load job started for %s. Check on the status of it here: ' +
'https://bigquery.cloud.google.com/jobs/%s', reportConfig.NAME,
CONFIG.BIGQUERY_PROJECT_ID);
return insertJob.jobReference.jobId;
}
/**
* Polls until all jobs are 'DONE'.
*
* @param {Array.<string>} jobIds The list of all job ids.
*/
function waitTillJobsComplete(jobIds) {
var complete = false;
var remainingJobs = jobIds;
while (!complete) {
if (AdsApp.getExecutionInfo().getRemainingTime() < 5){
Logger.log('Script is about to timeout, jobs ' + remainingJobs.join(',') +
' are still incomplete.');
}
remainingJobs = getIncompleteJobs(remainingJobs);
if (remainingJobs.length == 0) {
complete = true;
}
if (!complete) {
Logger.log(remainingJobs.length + ' jobs still being processed.');
// Wait 5 seconds before checking status again.
Utilities.sleep(5000);
}
}
Logger.log('All jobs processed.');
}
/**
* Iterates through jobs and returns the ids for those jobs
* that are not 'DONE'.
*
* @param {Array.<string>} jobIds The list of job ids.
*
* @return {Array.<string>} remainingJobIds The list of remaining job ids.
*/
function getIncompleteJobs(jobIds) {
var remainingJobIds = [];
for (var i = 0; i < jobIds.length; i++) {
var jobId = jobIds[i];
var getJob = BigQuery.Jobs.get(CONFIG.BIGQUERY_PROJECT_ID, jobId,{'location':CONFIG.LOCATION});
if (getJob.status.state != 'DONE') {
remainingJobIds.push(jobId);
}
}
return remainingJobIds;
}
function setDateRange(parameter){
var rangeStatement = ''
const now = new Date();
if(parameter == 'YESTERDAY'){
const yesterday = new Date(now.getTime() - 1000 * 60 * 60 * 24);
rangeStatement = '"'+ formatDate(yesterday) +'" AND "'+formatDate(yesterday)+'"'
} else {
var range = parameter.split(",")
const start = Date.parse(range[0])
const end = Date.parse(range[1])
rangeStatement = '"' + range[0] + '" AND "' + range[1] + '"'
}
return rangeStatement
}
// FORMAT A DATE TO yyyy-MM-dd
function formatDate(date){
const timeZone = AdsApp.currentAccount().getTimeZone();
date = Utilities.formatDate(date, timeZone, 'yyyy-MM-dd')
return date
}
Google Ads API Custom Call – tutorial.js hosted with ❤ by GitHub
